Relational database has been the most popular database type since 1990. It is based on the relational model, which means that the data will be stored in tables(=relations). So in this context the term relation means the same as table.
We can use SQL(Structured Query Language) to manage relational databases, so we can call them also SQL databases. SQL is a big benefit, because you can use it with all SQL databases. It means that, if you know how to use MySQL, you also know how to use SQL Server.
In recent years NoSQL databases have grown quite popular. They don't use the relational model, but they have some benefits compared to SQL databases. They can be much faster sometimes, but if the integrity of data is important, SQL databases are the one to choose. Some of the most used NoSQL databases are Google BigTable, Amazon Dynamo, MongoDB and Apache Cassandra.
A relational database matches data by using common characteristics found within the data set. The resulting groups of data are organized and are much easier for many people to understand.
For example, a data set containing all information about a library. We can divide the data to "groups": books, borrowers, borrows. Such a grouping uses the relational model.
A relational database is a collection of data items organized as a set of formally-described tables from which data can be accessed or reassembled in many different ways without having to reorganize the database tables. The relational database was invented by E. F. Codd at IBM in 1970.
The standard user and application program interface to a relational database is the structured query language (SQL). SQL statements are used both for interactive queries for information from a relational database and for gathering data for reports.
In addition to being relatively easy to create and access, a relational database has the important advantage of being easy to extend. After the original database creation, a new data category can be added without requiring that all existing applications be modified.
📊 Interactive Demonstration of Relational Databases
Relational database consists of below components:
- Tables
- Keys (primary key and foreign key)
- Relationships (between tables)
| id_book | name | author | isbn |
| 1 | Everything You Ever Wanted to Know | Upton | 082305649x |
| 2 | Photography | Vilppu | 205711499 |
| 3 | Drawing Manual | Zelanshi | 1892053039 |
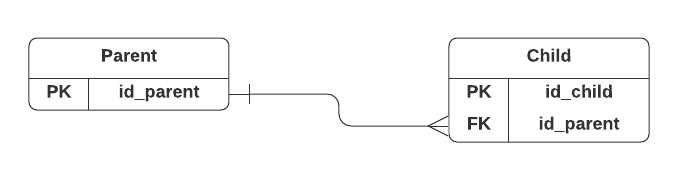
When there is a relationship between two tables, one of them is a parent table and the other one is a child table.
- Every table must have a primary key
- The child table must have a foreign key
| Relational term | SQL equivalent |
|---|---|
| relation, base relvar | table |
| derived relvar | view, query result, result set |
| tuple | row (record) |
| attribute | column (field) |
In relational database every table should have a unique key, which can uniquely identify each row in a table. A unique key comprises a single column
or a set of columns. Two distinct rows in a table can not have the same value (or combination of values) in those columns. This key is called primary key.
In the example below, the email is the primary key
CREATE TABLE person( email VARCHAR(50) PRIMARY KEY, fname VARCHAR(30), lname VARCHAR(30) );
If a suitable single field cannot be found to serve as the primary key of a table, a combination of multiple fields (a composite key) can be used instead. This composite key must uniquely identify each row in the table.
For example, in a table storing course enrollments, there may not be a single field that uniquely identifies a record. However, a combination of student_id and course_id can be used as a composite primary key, since together they uniquely identify each enrollment.
CREATE TABLE enrollments( id_student INT, id_course INT, enrollment_time TIMESTAMP, PRIMARY KEY(id_student, id_course) );
Sometimes there is no field(s), which could be the primary key (natural key) and then we have to add an extra field which will be the primary key. This kind of primary key is called a surrogate key.
Quite often the surrogate key is set to AUTO_INCREMENT, which means that it is an INTEGER with automatic values 1,2,3 ...
In the example below, id_person is the surrogate key.
CREATE TABLE person( id_person INT PRIMARY KEY AUTO_INCREMENT, fname VARCHAR(30), lname VARCHAR(30) );
- Uniqueness: Each surrogate key is unique across the table it is used in.
- Non-meaningful: The value of a surrogate key does not have a business meaning and is not derived from business data.
- Stability: Surrogate keys do not change if the data in the row changes.
- Simplicity: They are typically simple numeric values, which makes them easy to index and join.
- Simplicity: Easier to use as a primary key compared to composite or natural keys, which might involve multiple columns or complex data types.
- Stability: Remains constant even when the data in the table changes, reducing the risk of key updates.
- Performance: Often improves performance for indexing and join operations due to their simplicity and smaller size compared to natural keys.
- Lack of Business Meaning: Since surrogate keys do not contain business information, they do not provide any context or meaning outside the database.
- Additional Management: They require an additional column in the table and the logic to generate and manage them.
A foreign key is a field (in child table) that points to the primary key of another table (parent table). The purpose of the foreign key is to ensure referential integrity of the data. In other words, only values that are supposed to appear in the database are permitted.
So the foreign key is referencing to the primary key of the parent table, like this
For example, suppose we have two tables: a CUSTOMERS table that contains all customer data, and an ORDERS table that contains all orders placed by those customers. The constraint here is that all orders must be associated with a CUSTOMERS that is already in the CUSTOMERS table. In this case, we will place a foreign key on the ORDERS table and have it relate to the primary key of the CUSTOMERS table. This way, we can ensure that all orders in the ORDERS table are related to a CUSTOMERS in the CUSTOMERS table. In other words, the ORDERS table cannot contain information on a customer that is not in the CUSTOMERS table.
The structure of these two tables will be as follows:
Table CUSTOMERS
| column name | characteristic |
| idCustomers | Primary Key |
| Last_Name | |
| First_Name |
Table ORDERS
| column name | characteristic |
| idOrders | Primary Key |
| Order_Date | |
| Amount | |
| idCustomers | Foreign Key |
In the above example, the idCustomers column in the orders table is a foreign key pointing to the idCustomers column in the customers table.
First we can create the table customers with below SQL-code (in MySQL)
CREATE TABLE Customers( idCustomers integer primary key, Last_Name VARCHAR(45), First_Name VARCHAR(45) ) Engine=InnoDB;
Then we can create the orders table with below SQL-code (in MySQL)
CREATE TABLE Orders (idOrders integer primary key, Order_Date date, idCustomers integer, Amount double, Foreign Key (idCustomers) references Customers(idCustomers) ON UPDATE CASCADE ON DELETE RESTRICT) Engine=InnoDB;
The below ER-diagram will show the relationship between Customers and Orders:
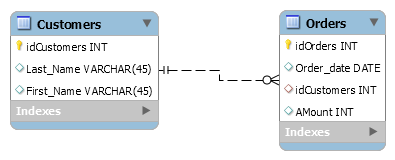
The following animation demonstrates how ON UPDATE CASCADE and ON DELETE RESTRICT work with the Customers and Orders tables:
| idCustomers | Last_Name | First_Name |
|---|---|---|
| 1 | Smith | John |
| 2 | Johnson | Mary |
| 3 | Williams | David |
| idOrders | Order_Date | idCustomers (FK) | Amount |
|---|---|---|---|
| 101 | 2024-01-15 | 1 | 250.00 |
| 102 | 2024-01-20 | 1 | 175.50 |
| 103 | 2024-02-10 | 2 | 89.99 |
| 104 | 2024-02-15 | 3 | 450.00 |
How the constraints work:
- ON UPDATE CASCADE: When a primary key value in the Customers table is updated, all matching foreign key values in the Orders table are automatically updated to the new value.
- ON DELETE RESTRICT: When attempting to delete a customer that has associated orders, the database prevents the deletion and returns an error. This maintains referential integrity by ensuring orders are never orphaned.
Indexes are essential components in relational databases, designed to improve the speed of data retrieval operations. Much like the index of a book, a database index allows the database engine to find rows of data quickly without scanning the entire table.
An index is a data structure that stores the values of one or more columns in a table along with pointers to the corresponding rows. This allows the database to locate data more efficiently.
The animation below shows the difference. The query searches for all persons with last name Miller.
SELECT * FROM person WHERE lname = 'Miller'
Without Index (full table scan)
| # | First Name | Last Name |
|---|---|---|
| 1 | James | Johnson |
| 2 | Anna | Anderson |
| 3 | Sam | Smith |
| 4 | Carol | Clark |
| 5 | Maria | Miller |
| 6 | David | Davis |
| 7 | Brian | Brown |
| 8 | Grace | Garcia |
With Index (index lookup)
| Index: lname (sorted) | Row → |
|---|---|
| Anderson | 2 |
| Brown | 7 |
| Clark | 4 |
| Davis | 6 |
| Garcia | 8 |
| Johnson | 1 |
| Miller | 5 |
| Smith | 3 |
The types of indexes supported by different database management systems differ from each other. In the following, I will introduce some examples about using indexes in MySQL.
Here is a code for creating a table named person
CREATE TABLE person( id_person INT PRIMARY KEY AUTO_INCREMENT, fname VARCHAR(30), lname VARCHAR(30), email VARCHAR(30), country VARCHAR(20), city VARCHAR(20), UNIQUE INDEX email_index(email), INDEX name_index(lname, fname) )
- The primary key is automatically indexed
- The unique index email_index will prevent using same email to several person and also it makes "search by email queries" faster
- The index name_index, will make "search by name queries" faster
Indexes significantly speed up query performance, especially for large datasets. They reduce the amount of data the database engine needs to scan, thus reducing I/O operations and improving response times.
While indexes enhance read operations, they can slow down write operations such as INSERT, UPDATE, and DELETE because the index itself needs to be updated. Therefore, it's essential to strike a balance and create indexes that optimize performance for your specific use cases without causing unnecessary overhead.
Proper indexing is crucial for database performance tuning. By understanding and implementing the right types of indexes, you can ensure efficient data retrieval and overall system efficiency.
An ER-model (Entity-Relationship model) is a visual representation of the structure of a database. It shows the entities (tables), their attributes (columns), and the relationships between them. ER-models are created during the database design phase, before implementing the actual database.
What is an ER-model used for?
- Database Planning: ER-models help you plan and visualize the database structure before writing any SQL code.
- Communication: They provide a clear, visual way to communicate the database design to stakeholders, developers, and database administrators.
- Documentation: The ER-model becomes part of the database documentation, making it easier to understand and maintain the database in the future.
- Identifying Problems: Creating an ER-model helps identify design issues early, such as many-to-many relationships that need to be resolved with junction tables.
- Normalization: ER-models help ensure the database is properly normalized and follows best practices.
An ER-model typically includes:
- Entities: Represented as rectangles (e.g., Customer, Order, Product)
- Attributes: The fields/columns within each entity
- Primary Keys (PK): Unique identifiers for each entity, often underlined or marked with a key symbol (🔑)
- Foreign Keys (FK): References to primary keys in other entities, marked with a link symbol (🔗)
- Relationships: Lines connecting entities, showing how they relate to each other
- Cardinality: Numbers or symbols (1, M, N) indicating relationship types (one-to-one, one-to-many, many-to-many)
Note: Throughout this page, you have already seen several ER-diagrams illustrating different database concepts. In the following sections, we will explore the different types of relationships that can exist between entities and how they are represented in ER-models.
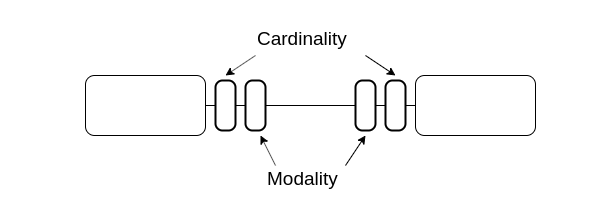
You define foreign keys in a database to model relationships in the real world. Relationships between real-world entities can be quite complex, involving numerous entities each having multiple relationships with each other. In databases there are two things which describes the relationship between two table: Cardinality and Modality.
In a relational database the relationship type (Cardinality) between two tables is one of below:
- one-to-one
- one-to-many
- many-to-many
In ER-diagrams, the relationship type is visually represented with symbols and lines:
- One-to-one relationship: Represented with "1" on both sides of the relationship line

- One-to-many relationship: Represented with "1" on one side and "M" or "∞" on the other

- Many-to-many relationship: Represented with "M" or "N" on both sides (must be resolved with a junction table)

Two tables are related in a one-to-one (1–1) relationship if, for every row in the first table, there is at most one corresponding row in the second table. One-to-one relationships are not very common in databases, but they have important use cases:
Common reasons for using one-to-one relationships:
- Security and Access Control: Sensitive information can be separated into its own table with different access permissions. For example, an Employee table might contain basic information (name, department, hire date), while a separate EmployeeSalary table contains confidential salary information that only HR can access.
- Performance Optimization: When a table has many columns but only a few are frequently accessed, the rarely-used columns can be moved to a separate table. This keeps the main table smaller and faster to query. For example, a Product table might have basic information, while detailed technical specifications are in a separate ProductDetails table.
- Optional Information: When certain attributes apply only to a subset of records, a one-to-one relationship avoids NULL values in the main table. For example, a Person table might link to a Driver table that contains driver's license information only for people who have a license.
- Separate Detailed Information: When extensive additional information is needed for some records, it can be stored in a separate table. For example, an Employee table with basic information and an EmployeeProfile table with extended details (bio, education history, certifications, skills) that are only needed occasionally.
Example: An online university has a Student table with basic information. Students who live in campus housing have additional information stored in a StudentHousing table (room number, building, roommate preferences). Not all students live on campus, so this is optional information stored in a separate table with a one-to-one relationship.
Two tables are related in a one-to-many (1–M) relationship if, for every row in the first table, there can be zero, one, or many corresponding rows in the second table. However, for every row in the second table, there is exactly one matching row in the first table. This type of relationship is also referred to as a parent-child or master-detail relationship.
One-to-many relationships are the most common type of relationship in relational databases. They naturally model many real-world situations where one entity owns or contains multiple related entities.
Common examples of one-to-many relationships:
- Customer and Orders: One customer can place many orders, but each order belongs to exactly one customer.
- Department and Employees: One department has many employees, but each employee works in exactly one department (in a simplified model).
- Author and Books: One author can write many books, but each book (in a simplified model) has exactly one primary author.
- Category and Products: One product category contains many products, but each product belongs to exactly one category.
- Teacher and Classes: One teacher teaches many classes, but each class is taught by exactly one teacher.
How it works: The "many" side (child table) contains a foreign key that references the primary key of the "one" side (parent table). For example, in a Customer-Orders relationship, the Orders table has a customer_id foreign key that points to the Customer table's primary key.
Two tables are related in a many-to-many (M—M) relationship when for every row in the first table, there can be many rows in the second table, and for every row in the second table, there can be many rows in the first table.
Common examples of many-to-many relationships:
- Customers and Products: One customer can order many products, and one product can be ordered by many customers.
- Students and Courses: One student can enroll in many courses, and one course can have many students enrolled.
- Authors and Books: One author can write many books, and one book can have many authors (co-authors).
- Actors and Movies: One actor can appear in many movies, and one movie can have many actors.

Important: Many-to-many relationships cannot be directly modeled in relational database systems. These types of relationships must be divided into two one-to-many relationships by introducing a junction table (also called a bridge table, linking table, or associative entity).
Example: To implement a many-to-many relationship between Customers and Products, we create a junction table called OrderItems (or Orders). This table contains foreign keys referencing both Customers and Products:
The solution with a junction table:

How the junction table works:
- The junction table has foreign keys to both parent tables (Customers and Products)
- Each row in the junction table represents one connection between a customer and a product
- Additional information about the relationship can be stored in the junction table (e.g., quantity, price, date)
- This converts the M:M relationship into two 1:M relationships:
- One Customer → Many OrderItems (1:M)
- One Product → Many OrderItems (1:M)
An identifying relationship is a type of relationship in database design where a child entity cannot exist without a parent entity. This is common in Entity-Relationship (ER) models.
In an identifying relationship, the primary key of the child entity includes the primary key of the parent entity. This means that the identity of the child depends on the parent.
For example, consider the entities Customer and Order. An order must belong to a customer. Therefore, the Order entity cannot exist without the Customer entity. The primary key of Order might be a combination of CustomerID and OrderNumber, forming an identifying relationship.
Key characteristics of an identifying relationship include:
- The child entity depends on the parent for identification.
- The child’s primary key includes the parent’s primary key.
- In ER diagrams, it is typically represented with a solid line.
By contrast, in a non-identifying relationship, the child entity has its own primary key, and the parent’s key is used only as a foreign key.
Identifying relationships are important for maintaining data integrity when entities are tightly linked, ensuring that child data cannot exist without its associated parent data.
In ER-diagram the identifying relationship is marked with solid line, while non-identifying relationships are marked with dashed lines.
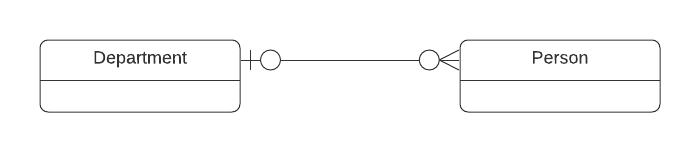
The participation of an entity in a relationship is either optional or mandatory. In ER-model the "inner symbol" indicates is it optional or mandatory. ( | = mandatory, 0 = optional).
- Both ends mandatory : in this case Person must belong to Department and Department can not exists without Person.

- One end mandatory, other end optional : in this case Person must belong to Department, but Department can exists without Person.
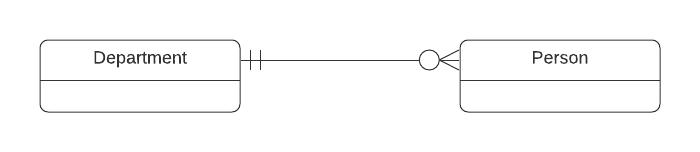
- One end mandatory, other end optional : in this case Person does not have to belong to Department, but Department can't exists without Person.
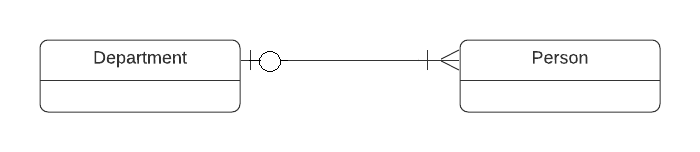
- Both ends optional : in this case Person doesn't have to belong to Department and Department can exists without Person.
So, neither entity is mandatory.
Modality is a term which describes if the relationship is mandatory or optional.
A feature provided by relational database management systems (RDBMS's) that prevents users or applications from entering inconsistent data. Most RDBMS's have various referential integrity rules that you can apply when you create a relationship between two tables.
For example, suppose that childTable has a foreign key that points to a field in parentTable.
- Referential integrity rule would prevent you from adding a record to childTable that cannot be linked to parentTable
- Referential integrity might prevent you to delete a row from the parentTable, if that row has child rows. This is called restrict rule
- Referential integrity rules might also specify that whenever you delete a record from parentTable, any records in childTable that are linked to the deleted record will also be deleted automatically. This is called cascading delete
- Referential integrity rules could specify that whenever you modify the value of a linked field in parentTable, all records in childTable that are linked to it will also be modified accordingly. This is called cascading update
The purpose of referential integrity is to take care that all the values of foreign key exists on the parent-table.
- Restrict:
- Disallows the update or deletion of referenced data
- Cascade:
- When referenced data is updated, all associated dependent data is correspondingly updated. When a referenced row is deleted, all associated dependent rows are deleted.
- Set to null:
- When referenced data is updated or deleted, all associated dependent data is set to NULL.
- Set to default:
- When referenced data is updated or deleted, all associated dependent data is set to a default value.
Interactive demonstration of DELETE rules:
| idCustomers | Last_Name | First_Name |
|---|---|---|
| 1 | Smith | John |
| 2 | Johnson | Mary |
| 3 | Williams | David |
| idOrders | Order_Date | idCustomers (FK) | Amount |
|---|---|---|---|
| 101 | 2024-01-15 | 1 | 250.00 |
| 102 | 2024-01-20 | 1 | 175.50 |
| 103 | 2024-02-10 | 2 | 89.99 |
| 104 | 2024-02-15 | 3 | 450.00 |
When designing a database, you have to make decisions regarding how best to take some system in the real world and model it in a database. This consists of deciding which tables to create, what columns they will contain, as well as the relationships between the tables.
The benefits of a database that has been designed according to the relational model are numerous. Some of them are:
-
Data entry, updates and deletions will be efficient.
-
Data retrieval, summarization and reporting will also be efficient.
-
Since the database follows a well-formulated model, it behaves predictably.
-
Since much of the information is stored in the database rather than in the application, the database is somewhat self-documenting.
-
Changes to the database schema are easy to make.
- Determine the purpose of the database - This helps prepare for the remaining steps.
- Find and organize the information required - Gather all of the types of information to record in the database.
- Divide the information into tables - Divide information items into major entities or subjects, such as Products or Orders. Each subject then becomes a table.
- Turn information items into columns - Decide what information needs to be stored in each table. Each item becomes a field, and is displayed as a column in the table.
- Specify primary keys - Choose each table's primary key. The primary key is a column, or a set of columns, that is used to uniquely identify each row.
- Set up the table relationships - Look at each table and decide how the data in one table is related to the data in other tables. Add fields to tables or create new tables to clarify the relationships, as necessary.
- Refine the design - Analyze the design for errors. Create tables and add a few records of sample data. Check if results come from the tables as expected. Make adjustments to the design, as needed.
- Apply the normalization rules - Apply the data normalization rules to see if tables are structured correctly. Make adjustments to the tables
The process of database design is divided into different parts. It consists of a series of steps.They are
- Requirement Analysis
- Conceptual Database Design (ER-Diagram)
- Logical Database Design (Tables, Normalization etc)
- Physical Database design (Table Indexing, Clustering etc)
Requirement analysis is made in order to identify and document the client's needs and desires of the implemented system. All the requirements can't usually get immediately recognized, so with the customer has to agree exactly how the additions and changes in the development of the project will be made. Often, it makes sense to do a so-called prototype, which can ensure that the requirements are correctly understood.
Requirements are made with the customer. Requirements typically include the following issues for the scheme:
- Introduction: who will be the users of the software and what are the targets of the system.
- Actions: Describe the functions needed for the system in general. Requirements should be identified (numbered) and priorizised, for example, which properties are necessary or required, which important and which are only desirable.
- Information: Description of a system to manage the data in general.
- Connections: Describe the system's connections to other systems and the users and the operating environment. In addition, the user interface can be described, as well as connections to other computing devices.
- Other Features: describe the non-functional features such as performance, availability, recovery from error conditions, security, maintainability, portability, etc.
When you are planning a database, it would be handy to draw the first versions of the ER-model with paper and pencil. You will just check that there is no many-to-many relationships. And then you should start to add the columns in the diagram. You can find information about ER-model from
Interactive ER-Model Design Process:
Before you start to make tables, you should write the field definitions. In order to do that you should decide for every field:
- what is the datatype of this field
- is this field mandatory (so can it be null or not)
- for text field: what is the maximum length and is the field length fixed or not
- for numeric fields, is the value an integer or a decimal, and what is the maximum size or range it can have
- for date-types: do you need seconds, minutes etc.
- is this the primary key
- is this a foreign key
Normalization is the process of organizing data in a database. This includes creating tables and establishing relationships between those tables according to rules designed both to protect the data and to make the database more flexible by eliminating two factors: redundancy and inconsistent dependency.
Redundant data wastes disk space and creates maintenance problems. If data that exists in more than one place must be changed, the data must be changed in exactly the same way in all locations. A customer address change is much easier to implement if that data is stored only in the Customers table and nowhere else in the database.
There are a few rules for database normalization. Each rule is called a "normal form." If the first rule is observed, the database is said to be in "first normal form." If the first three rules are observed, the database is considered to be in "third normal form." Although other levels of normalization are possible, third normal form is considered the highest level necessary for most applications.
As with many formal rules and specifications, real world scenarios do not always allow for perfect compliance. In general, normalization requires additional tables and some customers find this cumbersome. If you decide to violate one of the first three rules of normalization, make sure that your application anticipates any problems that could occur, such as redundant data and inconsistent dependencies.
- There is no repeating groups (ex. reservation1, reservation2, reservation3, ...) in any table
- There is no multipart fields (ex. Streetaddress Postalcode Postplace) in any table
All nonkey attributes are totally functionally dependent of the whole primary key (not part of the key).
All nonkey attributes are functionally dependent only upon the primary key (they are not dependent of any nonkey attribute).
Optimizing a relational database involves a series of best practices and techniques aimed at improving performance, ensuring efficient data retrieval, and maintaining data integrity. Here are some key strategies to optimize your relational database.
Proper indexing is crucial for query performance. Indexes allow the database to locate and retrieve data quickly. Focus on indexing columns that are frequently used in WHERE clauses, JOIN operations, and as foreign keys.
Write efficient SQL queries. Avoid using SELECT * and instead, specify only the columns you need. Use JOINs appropriately and ensure that your queries leverage indexes effectively.
SELECT id, name FROM Users WHERE age > 25;Normalize your database to reduce redundancy and ensure data integrity. However, in some cases, denormalization can improve performance by reducing the number of JOIN operations.
Perform regular maintenance tasks such as updating statistics, rebuilding indexes, and checking for database consistency. These tasks help maintain optimal performance.
Choose the most appropriate data types for your columns. Using the correct data type can save space and improve query performance. For example, use INTEGER for numeric data instead of VARCHAR. But, remember that you should not use INTEGER example for phonenumbers or postalcodes.
Continuously monitor your database performance using tools and logs. Analyze slow queries and understand their execution plans to identify bottlenecks and areas for improvement.
Optimizing a relational database is an ongoing process that involves careful planning, regular maintenance, and continuous monitoring. By implementing these strategies, you can significantly enhance the performance and reliability of your database.
In a database context, selectivity (also known as the "selectivity factor") refers to a metric that describes how well certain indexes or queries can differentiate between records. It essentially measures the fraction of rows selected relative to the total number of rows in a table when executing a specific query or using a particular index.
Low Selectivity: If a query returns only a small portion of the total rows in a table, the selectivity is low. This is usually desirable, as low selectivity means the query is very specific and the index is efficient.
High Selectivity: If a query returns a large portion of the rows in the table, the selectivity is high. This might indicate that the index is not very efficient or the query is too broad.
In the example there is person table with 10 rows. If you run a query that returns 3 rows, the selectivity is 30%. If the query returns 2 rows, the selectivity is 20%.
SELECT * FROM person WHERE country = 'Finland';This query returns 3 persons out of 10, so the selectivity is 30%.
SELECT * FROM person WHERE city = 'Helsinki';
This query returns 2 persons out of 10, so the selectivity is 20%. This means the condition is more selective than the first one, and an index on the city field can be effective in optimizing this query.
- Index Design: Low selectivity is a good indicator that an index can improve query performance. If an index is selective, it significantly reduces the number of rows that need to be scanned.
- Query Optimization: Database query optimizers use selectivity to assess which indexes to use for improving query performance.
- Resource Management: Understanding selectivity helps database administrators make better decisions regarding resource usage and query performance.
Selectivity is thus a crucial tool in optimizing database performance and designing effective indexes.