Versionhallinta on tietokoneohjelmien kehityksessä käytetty käytäntö, joka mahdollistaa projektin koodin historian seuraamisen ja hallinnan. Sen avulla voi tallentaa koodin eri versiot projektin edetessä, mikä helpottaa tiimityöskentelyä, virheiden jäljittämistä ja eri ominaisuuksien kehittämistä samanaikaisesti. Yleisiä versionhallintajärjestelmiä ovat esimerkiksi Git ja Subversion.
Git on hajautettu versionhallintajärjestelmä, joka on suunniteltu tehokkaaseen koodin seurantaan ja hallintaan ohjelmistoprojekteissa. Git tallentaa koodin versiot "commit"-nimellä tunnetuiksi tiloiksi, jolloin kehittäjät voivat seurata, palauttaa ja yhdistää muutoksia helposti. Se mahdollistaa myös samanaikaisen työskentelyn useiden kehittäjien kanssa ja helpottaa haarautumista ja yhdistämistä (branching and merging). Git on laajalti käytetty työkalu avoimen lähdekoodin ja suljetun lähdekoodin projekteissa.
Git-repository (repo) on paikka, jossa Git tallentaa ja hallinnoi projektin koodin, tiedostojen ja historian. Se voi olla joko paikallinen(local) eli omalla koneellasi tai etäinen(remote) eli Git-palvelimella, kuten GitHub, GitLab tai Bitbucket. Repository sisältää kaikki projektin tiedot, kuten eri versiot koodista (commitit), haarat (branches), ja mahdollisesti myös etätiedostopalvelimien osoitteet. Kehittäjät voivat kloonata (kopioda) repositorion itselleen, tehdä muutoksia ja sitten lähettää (push) muutokset takaisin repositorioon tai jakaa niitä muiden kehittäjien kanssa.
Git commit on toimenpide, joka tallentaa muutokset projektin koodiin Git-repositoriossa. Se luodaan, kun kehittäjä on tehnyt haluamansa muutokset ja haluaa pysyvästi tallentaa ne historian osaksi. Jokainen commit on kuin virstanpylväs, joka sisältää koodin tilan tietyllä hetkellä ja siihen liittyvän viestin, joka kertoo, mitä muutoksia on tehty. Commitit mahdollistavat projektin historian seuraamisen, virheiden jäljittämisen ja tiimityöskentelyn helpottamisen.
Git staging on vaihe ennen commitia, jossa kehittäjä valitsee ja valmistelee ne muutokset, jotka sisällytetään seuraavaan commitiin. Kehittäjä voi lisätä muutokset staging-alueelle (englanniksi "stage" tai "index") valitsemalla ne tiedostot, jotka haluaa sisällyttää seuraavaan commitiin. Tämä mahdollistaa tarkemman kontrollin siitä, mitkä muutokset tallennetaan. Staging-alueella olevat tiedostot eivät vielä ole osa commitia, mutta ne ovat valmiina lisättäviksi siihen commit-käskyllä. Tämä mahdollistaa useiden muutosten tekemisen ja sitten valikoivasti valitsemisen, mitkä niistä sisällytetään seuraavaan commitiin.
Voit esimerkiksi lisätä tiedoston cat.c staging alueelle komennolla
git add cat.cUsein halutaan lisätä kaikki repon tiedostot stagin alueelle ja silloin voidaan käyttää komentoa
git add .jossa . tarkoittaa nykyistä kansiota. Silloin siis lisätään staging alueelle kaikki muut kansiot ja tiedostot nykyisestä kansiosta paitsi, ne jotka mainitaan tiedostossa .gitignore.
git commit -m "kuvaillaan mitä muutoksia on tehty"Kun repositoryssä kommitoidaan koodia, sinne syntyy ikään kuin palautuspisteitä, joiden tilaan koodi voidaan myöhemmin palauttaa. Työskentelyä voidaan kuvata seuraavasti:
start -----kirjoitetaan koodia ---COMMIT_1-----kirjoitetaan koodia ---COMMIT_2-----kirjoitetaan koodia ---COMMIT_3 ......
Komennolla git log, voit tarkistaa mitä committeja on tehty. Tulos voi olla jotain tällaista:
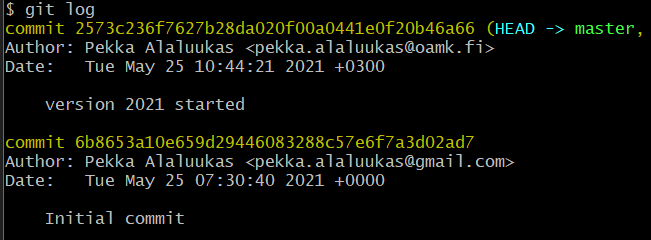
Jokaisella commitilla on yksilöllinen id ja niiden avulla koodi voidaan palauttaa vastaavaan tilaan. Esimerkiksi seuraavalla komennollaa koodi palautetaan siihen tilaan, jonka id alkaa koodilla 6b8653a1
git reset 6b8653a1
Haara (branch) Gitissä on erillinen kehityslinja, joka mahdollistaa koodin muutosten eristämisen pääkehityslinjasta (yleensä nimeltään master tai main). Haarat antavat kehittäjille mahdollisuuden työskennellä itsenäisesti uusien ominaisuuksien tai korjausten parissa ilman, että ne vaikuttavat suoraan pääkehityslinjaan.
- Haara on kuin erillinen polku, jossa koodi voi kehittyä eri suuntiin.
- Kehittäjät voivat luoda, poistaa ja vaihtaa haaroja.
- Haarat auttavat hallitsemaan ja eristämään muutoksia ennen niiden yhdistämistä pääkehityslinjaan.
- Tämä mahdollistaa rinnakkaisen työskentelyn ja helpottaa tiimityöskentelyä.
Voit siirtyä haarasta toiseen komennolla git checkout. Esimerkiksi seuraavalla komennolla siirrytään haaraan hotfix1
git checkout hotfix1edellinen toimii, jos hotfix1 haara on jo olemassa. Jollei sitä ole vielä luotu, voidaan käyttää komentoa
git checkout -b hotfix1tällöin Git luo uuden haaran nimeltään hotfix1, joka on identtinen sen haaraan kanssa, josta komento suoritettiin
Gitissä merge on toimenpide, joka yhdistää kahden haaran muutokset yhdeksi haaraksi. Tämä tarkoittaa, että koodimuutokset, jotka on tehty toisessa haarassa, lisätään toiseen haaraan.
- merge yhdistää kahden haaran muutokset yhteen.
- sitä käytetään yhdistämään uudet ominaisuudet tai muutokset pääkehityslinjaan (yleensä master tai main).
- git merge branch_name yhdistää branch_name-haaran nykyiseen haaraan.
Tiedostossa .gitignore mainittuja tiedostoja ja kansioita, ei lisätä staging alueelle. Sen sisältö voisi olla vaikka seuraava:
password.txt
*.exe
*.docx
Tällön tiedostoja password.txt ja exe- sekä docx- päätteisiä tiedostoja ei lisätä staging alueelle vaikka annetaan komento git add .
Komennolla git clone remote-repo lataat etärepon paikalliselle tietokoneellesi.
Voit forkata myös repot, jotka eivät ole omiasi. Kun forkkaat repon, sinulla on oma kopio siitä oman tilisi sisällä. Joten voit forkata repon etäpalvelimessa ja sitten kloonata oman kopioidun reposi tietokoneellesi. Alkuperäinen repo ja forkattu repo ovat toisistaan riippumattomia.