Tässä oppaassa käsitellään C++ kieltä ja sen olio-ominaisuuksia. Oppaan lähtökohtana, on että lukija on ohjelmoinut C-kielellä.
Aiheeseen liittyviä video-oppaita löytyy sivulta https://www.youtube.com/playlist?list=PLWl0bS7jZq9_6i4B1l4Im6sx9DKwUo7OU
Oppaaseen liittyvien esimerkkien lähdekoodit löytyy sivulta https://github.com/orgs/olio-kurssi/repositories.
Olio-ohjelmoinnin tärkeimmät käsitteet ovat luokka ja olio. Voisit ajatella, että luokka on ohjelmoijan tekemä uusi muuttujatyyppi ja olio muuttuja, jonka tyyppinä on tuo luokka. Voit siis verrata sitä tilanteeseen, jossa määrittelet muuttujan lauseella int age;. Samalla tavalla määrittelet olion lauseella Student myObject;. Sinun on kuitenkin itse luotava tuo luokka nimeltään Student.
Milloin on tarpeen luoda luokka ja olio?
Esimerkiksi teet sovelluksen, jossa käsittelet opiskelijoiden tietoja. Jokaiselle opiskelijalle määritellään nimi, syntymävuosi, osoite, sähköpostiosoite ja puhelinnumero. Yhdelle opiskelijalle sinun on luotava 5 muuttujaa. Jos käsittelet 10 opiskelijan tietoja, sinun on luotava 50 muuttujaa.
Edellistä parempi ratkaisu on luoda tietue, jossa määritellään nuo 5 muuttujaa. Ja sitten luot 10 muuttujaa, joiden tyyppinä on tuo tietue.
Miksi luoda luokka, jos tietuekin toimii?
Paitsi, että luokan sisään voidaan sijoittaa useita muuttujia eli jäsenmuuttujia, voidaan luokan sisään sijoittaa myös metodeja eli jäsenfunktioita. Niiden avulla voit esimerkiksi antaa edellä mainituille jäsenmuuttujille arvoja hallitummin. Ja voit luoda metodeja jotka tulostavat noiden muuttujien arvoja haluamallasi tavalla.
Kun tehdään graafisia sovelluksia tarvitaan paljon buttoneita, tekstikenttiä, labeleita, alasvetovalikoita jne. Yleensä käytetään jotain valmiita kirjastoja tai frameworkkejä. Niissä on valmiiksi tehtynä esimerkiksi Button luokka, jolla on ominaisuuksia: buttonissa oleva teksti, klikkauksen aiheuttama tapahtuma, buttonin väri, reunojen tyyli jne. Aina kun laitamme omaan sovellukseemme buttonin, luomme Button luokan olion. (Qt frameworkissä luokka on QPushButton)
Mikä on Qt?
C++-sovellusten luominen on helpompaa, jos käytetään siihen tarkoitettua ohjelmointiympäristöä, kuten Qt Creatoria.
Qt-framework on cross-platform kirjasto, jolla voidaan luoda graafisia sovelluksia eri alustoille (Windows, Linux, macOS). Qt sisältää joukon valmiiksi tehtyjä luokkia, joita voimme hyödyntää. Kun asennat Qt:n, saat mukaan myös Qt Creator -kehitysympäristön. Qt Creator on graafinen sovellus, jolla voidaan luoda Qt-sovelluksia ja myös C- ja C++-sovelluksia.
C++ ohjelmointi
Aluksi on syytä tutustua kuinka C++ kielessä tulostetaan konsolin ruudulle ja kuinka sieltä luetaan käyttäjän antamaa dataa. Voit toki käyttää C-kielestä tuttuja funktioita printf ja scanf, mutta niiden sijaan käytetään yleensä olioita: cout ja cin. Molemmat ovat iostream luokan olioita, joten niitä käyttäessäsi sinun tulee lisätä kooditiedostoon alkuun rivi
#include <iostream>
C++ kielessä voidaan käyttää merkkijonoille muuttujatyyppiä string, jota C-kielessä ei ole. C-kielessähän merkkijonoille käytettiin char -taulukkoja. Tuo string, samoin kuin cout ja cin on määritetty nimiavaruudessa eli namespace:ssa nimeltään std.
Voisit tehdä lyhyen ohjelman koodilla
#include <iostream>
int main()
{
std::string name;
std::cout<<"Kerro nimesi"<<std::endl;
std::cin>>name;
std::cout<<"Terve "<<name<<std::endl;
return 0;
}
Koska tuohon std namespaceen joudutaan edellä viittamaan monta kertaa, voisi koodiin lisätä tuon namespacen käyttäen using direktiiviä seuraavasti:
#include <iostream>
using namespace std;
int main()
{
string name;
cout<<"Kerro nimesi"<<endl;
cin>>name;
cout<<"Terve "<<name<<endl;
return 0;
}
Varoitus: using namespace std; suurissa projekteissa
Vaikka using namespace std; tekee koodista lyhyemmän ja helpommin luettavan pienissä ohjelmissa, se ei ole suositeltava käytäntö isommissa projekteissa seuraavista syistä:
- Nimien törmäykset: Jos käytät useita kirjastoja, saattaa eri kirjastoissa olla samannimisiä funktioita tai luokkia. Esimerkiksi jos sinulla on oma
count-funktio ja käytätusing namespace std;, voi syntyä ristiriita std::count-funktion kanssa. - Koodin selkeys: Isommissa projekteissa ei ole aina selvää, mistä tietty funktio tai luokka tulee.
std::couton selvempi kuin pelkkäcout. - Header-tiedostoissa:
using namespace std;tulee välttää .h-tiedostoissa, koska se pakottaa kaikki tuon headerin includettavat tiedostot käyttämään koko std-nimiavaruutta.
Parempia vaihtoehtoja:
- Käytä std::-etuliitettä:
std::cout,std::stringjne. - Tuo vain tarvittavat nimet:
using std::cout; using std::string;- näin otat käyttöön vain tietyt nimet, ei koko nimiavaruutta
Tämän oppaan esimerkeissä käytetään using namespace std; yksinkertaisuuden vuoksi, jotta voit keskittyä olio-ohjelmoinnin oppimiseen. Kun siirryt tekemään isompia projekteja, harkitse std::-etuliitteen käyttöä.
Olio-ohjelmoinnin kaksi keskeistä termiä ovat luokka ja olio. Olio-ohjelmoinnissa tieto ja sitä käsittelevä toiminnallisuus kootaan luokkarakenteeksi. Luokista luodaan olioita.
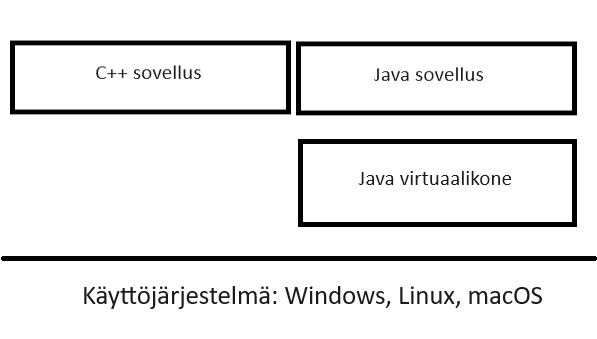
Olio-ohjelmointia tukevia kieliä ovat mm. C++, C#, Java ja Visual Basic. C++ poikkeaa muista edellä mainituista siten, että C++ sovelluksia ajetaan suoraan käyttöjärjestelmän päällä. Muilla edellä mainituilla kielillä tehdyt sovellukset ajetaan virtuaalikoneessa. Edellä mainitun eron vuoksi C++ sovellukset vaativat vähemmän resursseja koneelta ja toimivat näin nopeammin, varsinkin heikkotehoisissa koneissa. Haittapuolena on, että C++ sovelluksen ohjelmoiminen on työläämpää. C++ ohjelmoijan tulee itse huolehtia esimerkiksi muistin varaamisesta ja vapauttamisesta, kun muissa em. kielissä virtuaalikone huolehtii siitä.
Alla olevassa kuvassa kuvataan C++ - ja Java-sovelluksen toimintaa.
Tärkeimpiä olio-ohjelmoinnin periaatteita ovat kapselointi, tiedon kätkentä, periytyminen ja polymorfismi.
Kapselointi tarkoittaa, että olion tiedot ja toiminnot yhdistetään yhdeksi yksiköksi. Olio piilottaa sisäiset tietonsa ja tarjoaa julkisen rajapinnan, jonka avulla ohjelmoija voi käyttää olion toiminnallisuutta ilman, että olion sisäinen rakenne paljastuu. Kapselointi mahdollistaa ohjelmiston rakenteen selkeyttämisen ja tietojen suojaamisen ulkopuolisilta.
Tiedon kätkentä liittyy läheisesti kapselointiin. Tiedon kätkennällä pyritään rajoittamaan pääsyä olion sisäisiin tietoihin, mikä estää ulkopuolisia muuttamasta tai väärinkäyttämästä niitä. Tämä saavutetaan määrittelemällä olion tietojen näkyvyys private, protected tai public -avainsanojen avulla. Tiedon kätkentä auttaa pitämään ohjelmiston vakaana ja virheettömänä.
Periytyminen tarkoittaa, että olio voi periä ominaisuuksia ja toimintoja toiselta oliolta. Periytyminen mahdollistaa yhteisten ominaisuuksien uudelleenkäytön ja laajentamisen, mikä vähentää koodin määrää ja parantaa ohjelmiston ylläpidettävyyttä. Esimerkiksi "Eläin" voi olla perusluokka, josta "Koira" ja "Kissa" voivat periä ominaisuuksia, kuten liikkuminen ja hengittäminen.
Polymorfismi tarkoittaa, että sama operaatio voi toimia eri tavoilla eri olioilla. Se mahdollistaa yhteisen rajapinnan käytön erilaisille olioille, jolloin voimme kutsua esimerkiksi metodin ajaa() sekä "Auto"- että "Moottoripyörä"-olioille, vaikka niiden toiminta eroaisi toisistaan. Polymorfismi parantaa ohjelman joustavuutta ja laajennettavuutta.
Lisätietoa asiasta on harjoituksessa 3b.
Opiskeltuasi c-kieltä tietue lienee sinulle tuttu käsite. Myös C++ ohjelmassa voit luoda tietueita esimerkiksi seuraavasti:
typedef struct Person_struct{
int age;
string name;
}
person;
Nyt sinulla on käytössäsi uusi tietotyyppi ja voit luoda muuttujia, joilla on tietotyyppinä person seuraavasti:
person pe;Ja voit sijoittaa tietuemuuttujille arvoja seuraavasti:
pe.age=23; pe.name="Teppo Testi";Eli person-tietue sisältää muuttujat age ja name. Oheisen esimerkin sovellus, löytyy sivulta https://github.com/olio-kurssi/esim0
Luokka voisi olla samanlainen, mutta usein se sisältää myös metodeja, joiden avulla noita muuttujia käsitellään. Voidaan luoda Person luokka seuraavasti:
class Person{
private:
int age;
string name;
public:
int getAge() const {
return age;
}
void setAge(int value){
age=value;
}
string getName() const {
return name;
}
void setName(string value){
name=value;
}
};
Luokan sisältämiä muuttujia nimitetään jäsenmuuttujiksi ja luokan sisältämiä funktioita (jotka käsittelevät em. muuttujia) nimitetään jäsenfunktioiksi eli metodeiksi.
public osiossa määritelty getAge-metodi on age muuttujan Getter-metodi. Sen avulla saadaan haettua age muuttujan arvo. Ja setAge on age muuttujan Setter-metodi. Sen avulla muuttujan age arvo voidaan asettaa.
Molemmissa Gettereissä eli getAge ja getName on käytetty const määrettä metodin lopussa. Tämä kertoo, että metodi ei muuta olion tilaa (jäsenmuuttujia).
Miksi const-metodit ovat tärkeitä?
1. Kääntäjä estää vahingossa tapahtuvat muutokset
Kun merkitset metodin const:ksi, kääntäjä estää sinua muuttamasta jäsenmuuttujia metodin sisällä:
class Person {
int age;
public:
int getAge() const {
return age; // OK: vain lukeminen
}
void badGetter() const {
age = 25; // VIRHE: const-metodi ei voi muuttaa jäsenmuuttujia!
}
};
2. Const-oliot voivat kutsua vain const-metodeja
Jos luot const-olion tai käytät const-viittausta, voit kutsua vain const-metodeja:
void printPersonInfo(const Person &p) {
cout << p.getAge(); // OK: getAge() on const-metodi
// p.setAge(30); // VIRHE: setAge() ei ole const, ei voi kutsua!
}
3. For-silmukoissa const-viittausten kanssa
Kun käyt vektorin läpi const-viittauksilla, voit kutsua vain const-metodeja:
vector<Person> personList
// ... lisätään henkilöitä ...
for(const Person &p : personList) {
cout << p.getAge(); // OK: getAge() on const
// p.setAge(30); // VIRHE: setAge() ei ole const
}
4. Parempi dokumentaatio
Const-metodit kertovat muille ohjelmoijille (ja sinulle myöhemmin), että metodi ei muuta olion tilaa. Se on itsedokumentoivaa koodia.
Yhteenveto:
- Getter-metodit tulisi aina merkitä
const:ksi, koska ne vain lukevat tietoa - Setter-metodit eivät voi olla
const, koska ne muuttavat jäsenmuuttujia - Const-metodit mahdollistavat olioiden käytön const-viittauksilla ja const-parametreina
- Kääntäjä auttaa estämään virheet: jos yrität vahingossa muuttaa jäsenmuuttujaa const-metodissa, saat virheilmoituksen
Esimerkki hyvistä käytännöistä:
class Student {
private:
string name;
int age;
public:
// Getterit ovat const - eivät muuta olion tilaa
string getName() const { return name; }
int getAge() const { return age; }
// Setterit eivät ole const - muuttavat olion tilaa
void setName(string n) { name = n; }
void setAge(int a) { age = a; }
// Tulostusmetodi on const - ei muuta olion tilaa
void printInfo() const {
cout << name << ", " << age << " vuotta" << endl;
}
};
Suositus: Merkitse aina metodi const:ksi, jos se ei muuta olion tilaa. Tämä on hyvä C++-käytäntö ja auttaa välttämään virheitä.
Private tyyppisiin muuttujiin ja metodeihin päästään käsiksi vain luokan sisältä. Public tyyppisiin muuttujiin ja metodeihin päästään käsiksi myös luokasta luodun olion kautta. Protected tyyppisiin muuttujiin päästään käsiksi luokan ja perivän luokan sisältä. Usein noudatetaan seuraavia käytäntöjä:
- jäsenmuuttujista tehdään private tyyppisiä
- metodeista tehdään public tyyppisiä
Oheisen esimerkin sovellus, löytyy sivulta https://github.com/olio-kurssi/esim1
Yleensä luokan muuttujien ja metodien määrittelyt tehdään h-tiedostossa. Kun luodaan Person-luokka, niin person.h tiedoston sisältö voisi olla seuraava
#ifndef PERSON_H
#define PERSON_H
#include <iostream>
using namespace std;
class Person
{
public:
Person();
int getAge() const;
void setAge(int newAge);
string getFname() const;
void setFname(const string &newFname);
private:
int age;
string fname;
};
#endif // PERSON_H
Edellä siis private osiossa on määritelty jäsenmuuttujat age ja fname ja public osiossa niiden getterit ja setterit.
Ja tuossa h-tiedostossa määritetään metodeista vain niiden palautusarvon tyyppi ja metodin ottamien parametrien tyyppi. Luokan metodien toteutukset kirjoitetaan person.cpp tiedostoon seuraavasti:
#include "person.h"
Person::Person()
{
}
int Person::getAge() const
{
return age;
}
void Person::setAge(int newAge)
{
age = newAge;
}
string Person::getFname() const
{
return fname;
}
void Person::setFname(const string &newFname)
{
fname = newFname;
}
this on erityinen osoitin, joka viittaa olioon, jonka jäsenfunktiota parhaillaan suoritetaan. Se on implisiittinen parametri jokaisessa ei-staattisessa jäsenfunktiossa.
Milloin this on pakollinen?
- Kun parametrin ja jäsenmuuttujan nimet ovat samat
class Person { string name; public: void setName(string name) { this->name = name; // Pakollinen! Ilman this->name viittaisi parametriin } }; - Kun halutaan palauttaa viite olioon itseensä (method chaining)
class Person { string name; int age; public: Person& setName(string n) { name = n; return *this; // Pakollinen! Palautetaan olio itse } Person& setAge(int a) { age = a; return *this; } }; // Käyttö: voidaan ketjuttaa metodikutsuja Person p; p.setName("Teppo").setAge(25); - Kun olio täytyy välittää parametrina toiselle funktiolle
class Student { string name; public: void registerToSystem() { // Välitetään this-osoitin toiselle funktiolle systemDatabase.addStudent(this); } };
Milloin this on vapaaehtoinen?
Kun jäsenmuuttujien ja parametrien nimet ovat erilaiset, this-osoittimen käyttö on vapaaehtoista. Seuraavat ovat identtiset:
void setAge(int value) {
age = value; // Toimii ilman this
}
void setAge(int value) {
this->age = value; // Toimii myös this:llä (selkeämpi)
}
Hyvä käytäntö: Käytä aina erilaisia nimiä jäsenmuuttujille ja parametreille (esim. jäsenmuuttuja: age, parametri: value tai newAge), jolloin vältät this-osoittimen pakollisen käytön ja koodi on selkeämpi.
Olio on luokasta luotu ilmentymä eli instanssi. Voit verrata asiaa siihen, että int on muutujatyyppi ja voit luoda muuttujan lauseella int myVariable. Edellä olevassa esimerkissä on luotu luokka Person ja siitä voidaan luoda olio lauseella Person objectPerson.
Kun luot olioita sinun tulee ymmärtää, että sovelluksellasi on käytössä kahdenlaista muistia
- Stack eli pinomuisti
- Heap eli kekomuisti
Heap muistia allokoidaan dynaamisesti sovelluksen ajon aikana ja sinun on huolehdittava sen vapauttamisesta (jollet käytä smart pointteria).
Perinteisesti C++ ohjelmoinnissa olioita on voinut luoda kahdella tavalla eli joko
Person objectPerson1;tai näin
//luo osoitin, jonka tyyppinä Person Person *objectPerson2; //varaa osoittimelle muistia new operaattorilla objectPerson2 = new Person;Edellisen voit korvata myös yhdellä lauseella:
Person *objectPerson2 = new Person;
Ensin mainittu tapa luo ns. automaattisen olion Stack muistiin. Tässä tapauksessa käyttöjärjestelmä huolehtii olion muistinvarauksista ja vapauttamisista, olion luonnin ja tuhoamisen yhteydessä.
Jälkimmäinen tapa luo olion Heap muistiin ja sinun on huolehdittava sen tuhoamisesta, kun et enää tarvitse sitä.
Kun olet luonut olion, pääset sen avulla käsiksi Person luokan metodeihin. Niihin viitataan eri tavalla riippuen siitä teitkö olion Stack vai Heap muistiin. Esimerkiksi setAge metodia voidaan kutsua näin:
objectPerson1.setAge(23);
objectPerson2->setAge(23);
Sinun ei itse tarvitse tuhota oliota objectPerson1, mutta sinun on tuhottava olio objectPerson2, kun et sitä enää tarvitse. Se tapahtuu seuraavasti:
delete objectPerson2; //vapautetaan muisti objectPerson2 = nullptr; //osoitin ei enää osoita vapautettuun muistiinJälkimmäinen koodirivi on tarpeen, koska se estää ns. dangling pointer-tilanteen ja parantaa koodin turvallisuutta. Jos ei mainittua riviä lisätä ja yrität vahingossa deletoida olion uudelleen tai viitata olioon uudelleen, saat undefined behavior-tilanteen.
Undefined behavior voi johtaa ohjelman kaatumiseen, muistivirheisiin tai satunnaiseen toimintaan.
Käytä automaattista muistialuetta (pino), kun tiedät olion koon etukäteen ja se on suhteellisen pieni. Oliot automaattisella muistialueella tuhoutuvat automaattisesti, kun niiden käyttöalue (kuten funktio) päättyy. Tämä auttaa välttämään muistivuotoja. Automaattinen muistialue on nopeampi käyttää kuin keko, koska sen hallinta on yksinkertaisempaa.
Käytä dynaamista muistialuetta (keko), kun olion koko ei ole tiedossa etukäteen tai se on suuri. Olet vastuussa olion muistialueen vapauttamisesta käytön jälkeen delete-avainsanalla. Oliot dynaamisella muistialueella säilyvät olemassa, kunnes ne tuhotaan manuaalisesti
- Pisteoperaattoria (.) käytetään kun käsittelet oliota suoraan (pinomuistiin luotu olio tai viittaus).
- Nuolioperaattoria (->) käytetään kun käsittelet oliota osoittimen kautta (kekomuistiin luotu olio tai mikä tahansa osoitin).
Moderni C++ mahdollistaa resurssien hallinnan älykkäiden osoittimien avulla, mikä helpottaa muistin vapauttamista ja vähentää mahdollisuutta virheisiin.
C++ sisältää kolmenlaisia smart osoittimia:
- unique_ptr: Omistaa dynaamisesti allokoidun muistin ja huolehtii sen vapauttamisesta, kun osoitin poistuu käytöstä. Se ei ole kopioitavissa.
- shared_ptr: Jaettu älyosoitin, joka sallii useiden osoittimien osoittaa samaan resurssiin. Se pitää kirjaa viitteiden määrästä ja vapauttaa muistin, kun kaikki osoittimet ovat vapautettu.
- weak_ptr: Heikko osoitin, joka liittyy shared_ptr:iin, mutta ei vaikuta resurssin elinkaareen.
Smart pointer voidaan luoda koodilla:
#include <memory> unique_ptr<Person> objectPerson = make_unique<Person>();Edellä olio luodaan kekoon, mutta se tuhoutuu automaattisesti.
Smart pointer estää muistivuodot (memory leak) automaattisella muistinhallinnalla. Vertaillaan perinteistä osoitinta ja unique_ptr:ää:
Esimerkki 1: Perinteinen osoitin - muistivuoto!
void processData() {
Person* p = new Person();
p->setAge(25);
// Jos tässä tapahtuu virhe tai unohdetaan delete,
// muisti jää varatuksi = MUISTIVUOTO!
if (jokinEhto) {
return; // VIRHE: delete puuttuu, muisti vuotaa!
}
delete p; // Tähän ei koskaan päästä, jos jokinEhto == true
p = nullptr;
}
Esimerkki 2: unique_ptr - ei muistivuotoa!
void processData() {
unique_ptr<Person> p = make_unique<Person>();
p->setAge(25);
if (jokinEhto) {
return; // OK: unique_ptr vapauttaa muistin automaattisesti!
}
// unique_ptr vapauttaa muistin myös normaalin paluun yhteydessä
}
// Muisti vapautetaan AINA kun funktio päättyy
Esimerkki 3: Poikkeukset - perinteinen osoitin vs. unique_ptr
// HUONO: Perinteinen osoitin
void riskyFunction() {
Person* p = new Person();
// Jos seuraava rivi heittää poikkeuksen,
// delete-riviä ei koskaan suoriteta = MUISTIVUOTO!
someRiskyOperation();
delete p;
p = nullptr;
}
// HYVÄ: unique_ptr
void riskyFunction() {
unique_ptr<Person> p = make_unique<Person>();
// Vaikka poikkeus heitetään,
// unique_ptr vapauttaa muistin automaattisesti!
someRiskyOperation();
// Ei tarvitse delete:ä
}
unique_ptr:n käyttö metodeissa
unique_ptr<Person> p = make_unique<Person>();
// Metodien kutsu nuolioperaattorilla (kuten tavallinen osoitin)
p->setAge(30);
p->setName("Teppo");
// Ei tarvitse delete:ä - unique_ptr hoitaa kaiken!
Yhteenveto: Miksi unique_ptr on parempi?
- Muisti vapautuu automaattisesti, kun unique_ptr poistuu näkyvyysalueelta (scope)
- Toimii oikein myös poikkeusten yhteydessä
- Ei voi unohtaa delete-komentoa
- Ei voi vahingossa deletoida kahdesti
- Estää dangling pointer -ongelmat
- Koodi on turvallisempaa ja helpommin ylläpidettävää
Suositus: Käytä aina unique_ptr:ää (tai shared_ptr:ää) perinteisten osoittimien sijasta, kun luot olioita dynaamisesti heap-muistiin. Tämä on moderni C++ -käytäntö ja estää lukuisia muistiongelmia.
Kappaleessa Koostaminen selitetään mitä eroa unique- ja shared- pointtereilla on.
Viittaus (reference) on C++:n ominaisuus, jota ei ole C-kielessä. Viittaus on alias eli vaihtoehtoinen nimi muuttujalle. Se on vaihtoehto osoittimelle, mutta turvallisempi ja usein helpompi käyttää.
Viittauksen määrittely:
int age = 25; int &ageRef = age; // ageRef on viittaus age-muuttujaan ageRef = 30; // Muuttaa age-muuttujan arvon 30:ksi cout << age; // Tulostaa: 30
Ero osoittimeen:
| Ominaisuus | Viittaus (int &ref) | Osoitin (int *ptr) |
|---|---|---|
| Alustus | Pakollinen heti määrittelyssä | Ei pakollinen, voi olla nullptr |
| Muuttaminen | Ei voida vaihtaa osoittamaan toiseen muuttujaan | Voidaan vaihtaa osoittamaan toiseen muuttujaan |
| Syntaksi | Käytetään kuten tavallista muuttujaa | Vaatii * ja -> operaattoreita |
| Turvallisuus | Ei voi olla "tyhjä" | Voi olla nullptr, voi aiheuttaa virheitä |
Viittaus vs. Osoitin - Esimerkki:
int x = 10; // Viittaus int &ref = x; ref = 20; // Muuttaa x:n arvon 20:ksi cout << x; // 20 // Osoitin int *ptr = &x; *ptr = 30; // Muuttaa x:n arvon 30:ksi (vaatii *) cout << x; // 30 ptr = nullptr; // OK: osoitin voi olla nullptr int y = 20; // ref = y; // VIRHE: viittausta ei voi vaihtaa osoittamaan toiseen muuttujaan
Viittaukset parametreina (tärkein käyttötapa):
Viittaukset ovat erityisen hyödyllisiä funktioiden parametreina. Ne välttävät kopioinnin ja mahdollistavat muutosten tekemisen alkuperäiseen muuttujaan.
// Kopioi arvon (hidas isoilla olioilla)
void setAge1(Person p) {
p.setAge(25); // Muuttaa vain KOPION ikää, ei alkuperäistä!
}
// Viittaus (nopea, muuttaa alkuperäistä)
void setAge2(Person &p) {
p.setAge(25); // Muuttaa alkuperäisen olion ikää
}
// Const-viittaus (nopea, ei voi muuttaa - PARAS tapa lukemiseen)
void printPerson(const Person &p) {
cout << p.getName(); // Vain lukeminen, ei kopiointia
// p.setAge(30); // VIRHE: const-viittaus
}
Milloin käyttää viittausta vs. osoitinta:
- Käytä viittausta kun:
- Funktio saa parametrin jota se käsittelee (ei omista sitä)
- Haluat välttää kopioinnin
- Arvo on aina olemassa (ei voi olla "tyhjä")
- Käytä osoitinta kun:
- Arvo voi olla nullptr (valinnainen)
- Osoitin voi osoittaa eri olioihin eri aikoina
- Käytät dynaamista muistia (new/delete tai smart pointers)
Viittaus for-silmukassa:
Olet jo nähnyt viittauksen käytön for-silmukassa aiemmin oppaassa:
for(const Student &student : studentList) {
student.printStudentData(); // Ei kopiointia, nopea
}
Yhteenveto:
- Viittaus on alias muuttujalle, ei erillinen muuttuja
- Viittaus on turvallisempi kuin osoitin (ei voi olla nullptr)
- Käytä const-viittausta (
const Type&) funktioparametreissa kun haluat välttää kopioinnin mutta et halua muuttaa arvoa - Viittaus on yleensä parempi valinta kuin osoitin, kun arvo on aina olemassa
Edellä, jo kerrottiin, että luokan muodostin on metodi, jolla on sama nimi kuin itse luokalla. Muodostinta kutsutaan aina kun luokasta luodaan olio. Sillä ei ole koskaan paluuarvoa, eikä paluuarvoksi kirjoiteta edes sanaa void.
Voit lisätä muodostimelle parametrin tai useita parametrejä. Jos edellä muokattaisiin luokan muodostin h tiedostossa muotoon
Person(int value);Ja cpp-tiedostossa muotoon
Person::Person(int value)
{
age=value;
}
pitää olioa luotaessa antaa aina myös kokonaisluku eli olion voisi luoda näin:
Person objectPerson(46);TAI
Person *objectPerson=new Person(46);Tällöin 46 sijoitetaan age muutujan arvoksi. Nyt ei enää voi luoda oliota antamatta kokonaislukua, eli seuraavasta seuraisi virheilmoitus
Person *objectPerson=new Person;Jos halutaan, että molemmat toimii, tarvitaan kaksi muodostinta, jolloin h-tiedostoon kirjoitettaisiin
Person(); Person(int value);Huom! Edellä on kyse metodin ylikuormittamisesta, josta kerrotaan myöhemmin.
Luokan tuhoaja on myös saman niminen kuin luokka, mutta sen edessä on merkki ~ eli seuraava olisi h-tiedostossa
~Person();Ja seuraava cpp-tiedostossa
Person::~Person()
{
cout<<"Person luokan tuhoajaa kutsuttiin\n";
}
Jos koodisi olisi seuraava
Person *objectPerson=new Person; delete objectPerson; objectPerson=nullptr;Näkisit tekstin Person luokan tuhoajaa kutsuttiin. Luokan tuhoajaa kutsutaan siis aina, kun olio tuhotaan delete komennolla. Hyvän ohjelmointitavan mukaisesti tuhottuun olioon tulisi asettaa nullptr, kuten edellä.
Sinun ei ole pakko luoda luokalle tuhoajaa, koska kääntäjä luo automaattisesti "näkymättömän tuhoajan". Ohjelmoijan kannattaa luoda tuhoaja vain, jos haluaa lisätä siihen jotain koodia.
Oheiseen esimerkkiin liittyvä sovellus, löytyy sivulta https://github.com/olio-kurssi/esim2
C++ mahdollistaa funktioiden ylikuormittamisen (function overloading) eli sen, että saman nimisiä funktioita on useita, mutta niillä on erilaiset parametrit. Myös palautusarvot voivat olla erilaisia, mutta pelkät erilaiset paluuarvot eivät mahdollista ylikuormitusta, jos parametrit ovat samat. Kääntäjä valitsee funktion kutsussa annettujen argumenttien avulla sopivan funktion.
Esimerkki ylikuormittamisesta
void calcSum(int a, int b){
int sum=a+b;
cout<<"Kokonaislukujen summa = "<<sum<<endl;
}
void calcSum(double a, double b){
double sum=a+b;
cout<<"Desimaalilukujen summa = "<<sum<<endl;
}
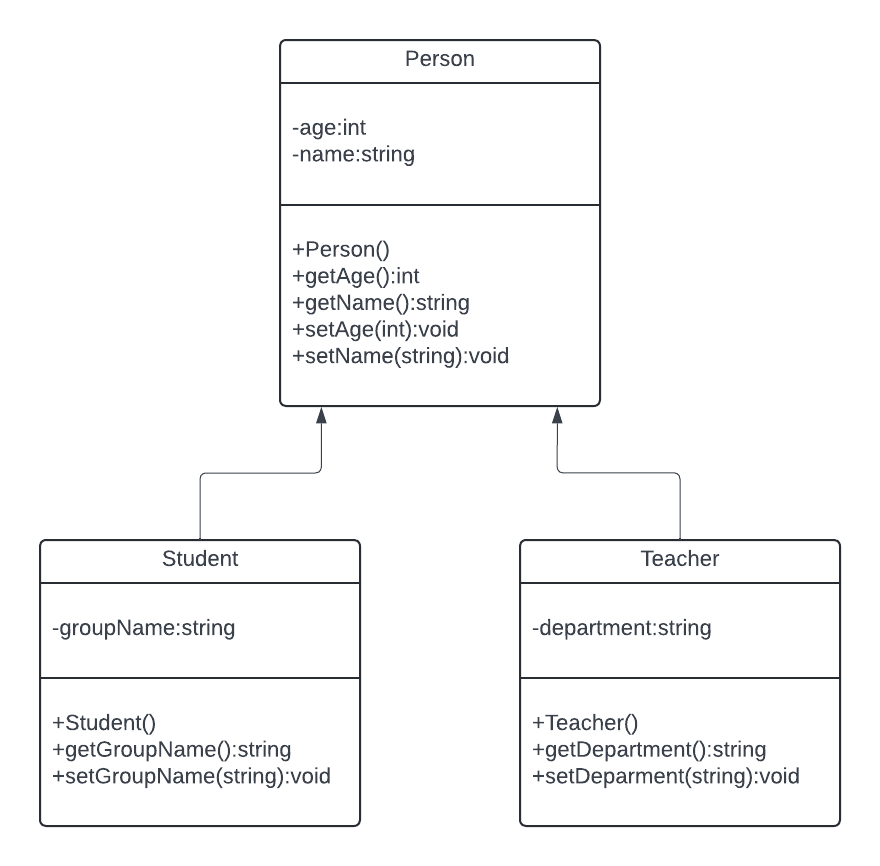
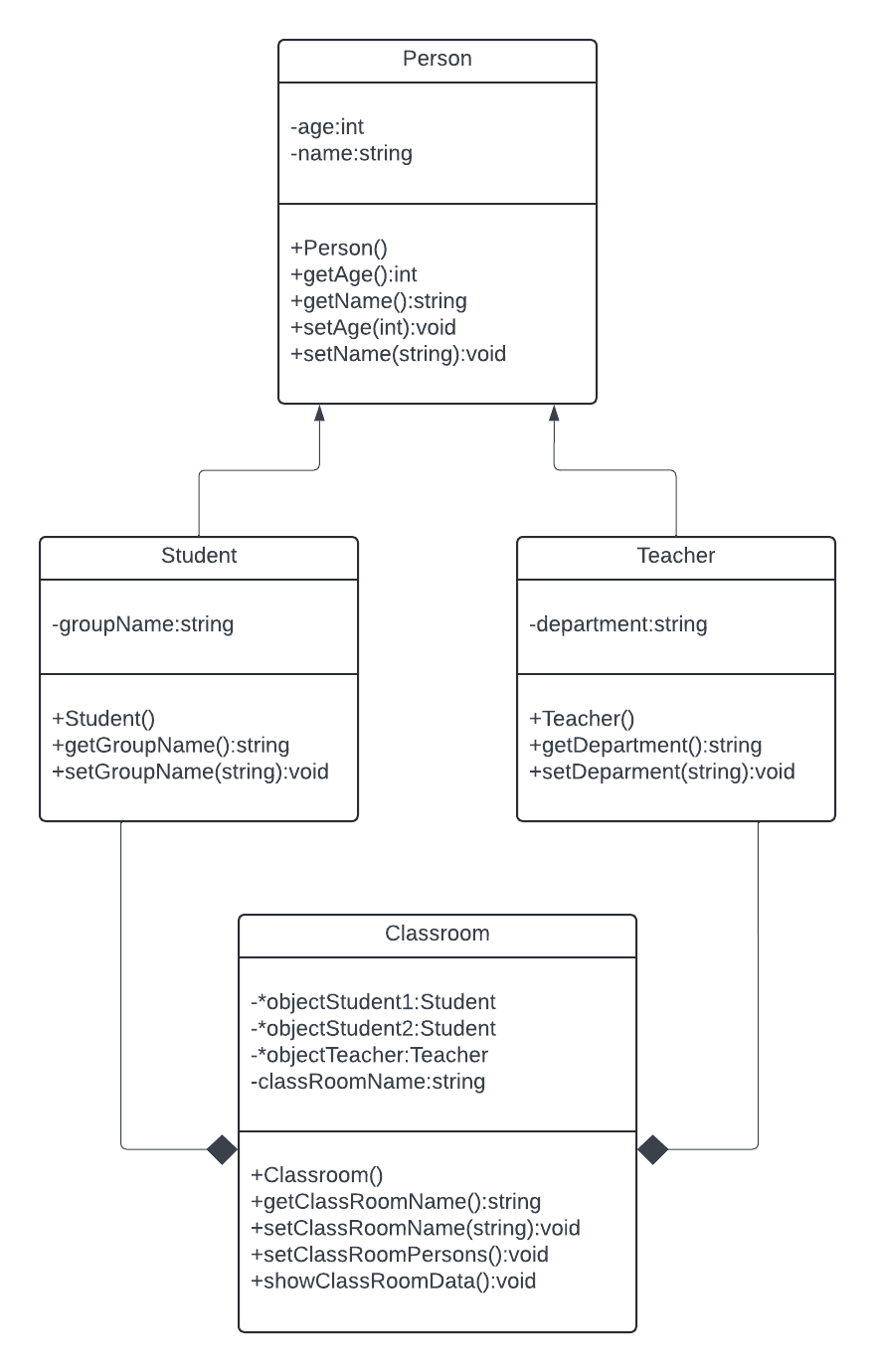
Periytyminen eli inheritance tarkoittaa, että jokin luokka voi periä toisen luokan. Ajatellaan esimerkiksi että rakentaisimme sovellusta, jolla käsitellään jonkin oppilaitoksen dataa. Todetaan, että oppilaitoksessa on opiskelijoita ja opettajia. Molemmilla on monia samalaisia ominaisuuksia, kuten esimerkiksi nimi ja syntymävuosi. Lisäksi opiskelijoilla on ryhmätunnus ja opettajilla on osasto.
Nyt voidaan tehdä niin, että
- luodaan kantaluokka Person, johon laitetaan kaikille yhteiset ominaisuudet
- luodaan luokka Student, joka perii luokan Person ja luokalla on lisäominaisuus groupName
- luodaan luokka Teacher, joka perii luokan Person ja luokalla on lisäominaisuus department
Perityminen merkitään Student-luokalle näin:
class Student : public Person
Oheiseen esimerkkiin liittyvä sovellus, löytyy sivulta https://github.com/olio-kurssi/esim3. Sovelluksen luokkakaavio näyttää seuraavalta:
Periytymisen yhteydessä on syytä tutustua termiin protected, kun luokka perii toisen luokan se pääsee käsiksi ominaisuuksiin, jotka ovat tyypiltään public tai protected. Seuraavassa taulukossa kuvataan kuinka private, public ja protected rajaavat oikeuksia.
| Pääsy | public | protected | private |
|---|---|---|---|
| Luokan sisällä | kyllä | kyllä | kyllä |
| Perivässä luokassa | kyllä | kyllä | ei |
| Luokan ulkopuolella | kyllä | ei | ei |
Edellä kuvattiin luokan jäsenten suojauksia. Periytymiselle voidaan määrittää perintämuoto seuraavilla vaihtoehdoilla:
- class Student : public Person
jolloin perivällä luokalla on pääsy perittävän public- ja protected-jäseniin - class Student : protected Person
jolloin perittävän luokan public-jäsenistä tulee perivän luokan protected-jäseniä - class Student : private Person
jolloin perittävän luokan public- ja protected-jäsenistä tulee perivän luokan private-jäseniä
| Kantaluokan näkyvyys | Näkyvyys perivässä luokassa eri perintämuodoilla | ||
|---|---|---|---|
| public-perintä | protected-perintä | private-perintä | |
| public | public | protected | private |
| protected | protected | protected | private |
| private | ei käytettävissä | ei käytettävissä | ei käytettävissä |
Student-luokan aliluokissa. Mieti siis perintämuotoa huolellisesti, jos Student-luokkaa aiotaan periyttää edelleen.
Voit lukea lisätietoa periytymisestä sivulta https://www.tutorialspoint.com/cplusplus/cpp_inheritance.htm
Mikäli peritävässä luokassa on muodostin, joka ottaa parametreja, voidaan perivän luokan muodostimessa kutsua tuota (kantaluokan) muodostinta.
Esimerkiksi, jos kantaluokassa Person on seuraava muodostin
Person::Person (string na){
name=na;
}
voisi perivän Student luokan muodostin olla seuraava
Student::Student(string gr, string na ) : Person(na){
groupName=gr;
}
Edellä name on Person luokan jäsenmuuttuja ja groupName on Student-luokan jäsenmuuttuja.
Jos edellä Person luokalla on oletusmuodostin (tyhjä muodostin) ja public tyyppinen metodi setName(), voitaisiin Student-luokan muodostin kirjoittaa muotoon:
Student::Student(string gr, string na ) {
groupName=gr;
this->setName(na);
}
Ylikirjoittaminen (overriding) C++-ohjelmoinnissa tarkoittaa, että aliluokka määrittelee uudelleen kantaluokassa määritetyn virtuaalisen metodin. Kun ylikirjoitettua metodia kutsutaan aliluokan instanssin kautta, suoritetaan aliluokan versio kyseisestä metodista. Tämä mahdollistaa polymorfismin, jossa aliluokka voi muokata kantaluokan toiminnallisuutta omien tarpeidensa mukaisesti.
Ylikirjoittaminen edellyttää, että sekä kantaluokan että aliluokan metodit ovat määritelty samalla nimellä, paluuarvolla ja parametreilla, ja kantaluokan metodin on oltava virtual-avainsanalla merkitty. Aliluokan metodi voidaan myös merkitä override-avainsanalla selkeyden vuoksi.
Seuraavassa esimerkissä lisäsin Person luokkaan metodin sayStatus ja ylikirjoitin sen Students ja Teacher luokissa.
Alla rivit h-tiedostoista
person.h virtual void sayStatus(); student.h virtual void sayStatus() override; teacher.h virtual void sayStatus() override;Ja cpp-tiedostossa metodien toteutukset ovat seuraavat
void Person::sayStatus()
{
cout<<"Person: ";
}
void Student::sayStatus()
{
cout<<"Opiskelija: ";
}
void Teacher::sayStatus()
{
cout<<"Opettaja: ";
}
Esimerkki löytyy sivulta https://github.com/olio-kurssi/esim4
C++-vektori on osa C++ Standard Libraryä ja se on dynaaminen taulukko, joka voi mukautua erilaisiin datamäärien muutoksiin. Se tarjoaa samankaltaisia ominaisuuksia kuin perinteinen taulukko, kuten nopea elementteihin pääsy, mutta toisin kuin perinteiset taulukot, vektorin koko voi muuttua joustavasti.
Esimerkki 1: Perinteinen taulukko
#include <iostream>
int main() {
int luvut[5] = {1, 2, 3, 4, 5};
for (int i = 0; i < 5; ++i) {
std::cout << luvut[i] << " ";
}
return 0;
}
Esimerkki 2: std::vector
#include <iostream>
#include <vector>
int main() {
std::vector<int> luvut = {1, 2, 3, 4, 5};
for (int luku : luvut) {
std::cout << luku << " ";
}
return 0;
}
Huomioita
std::vectoron turvallisempi ja joustavampi kuin perinteinen taulukko.- Vektorin kokoa ei tarvitse määrittää etukäteen.
- Vektori tarjoaa monia hyödyllisiä metodeja, kuten
push_back(),size(), jaat().
Jos sovelluksessa tarvitaan monta oliota samasta luokasta, voidaan niistä luoda lista vektorin avulla. Seuraavassa esimerkissä luodaan oliolista, joka sisältää Student-luokan oliota. Listan käytöstä erillisten olioiden sijaan on etuna se, että listaa voidaan käydä läpi toistorakenteella.
#include "student.h"
#include <iostream>
#include <vector>
using namespace std;
int main()
{
vector<Student> studentList;
// Luodaan olioita listaan
studentList.emplace_back("Teppo Testi", 1999, "TVT23SPL");
studentList.emplace_back("Liisa Joki", 1998, "TVT23SPL");
studentList.emplace_back("Aino Virta", 1997, "TVT23SPO");
studentList.emplace_back("Matti Virtanen", 2001, "TVT23SPO");
studentList.emplace_back("Mikko Vilkas", 2001, "TVT23SPL");
for(int x=0; x<=4; x++){
studentList[x].printStudentData();
}
return 0;
}
Edellä for silmukka voitaisiin korvata myös seuraavalla rakenteella, jossa ei tarvitse tietää montako alkiota vektorissa on.
for(Student student: studentList){
student.printStudentData();
}
Huom! Kopiointi vs. viittaus for-silmukassa
Edellä esitetty for-silmukka kopioi jokaisen opiskelijan uuteen muuttujaan student. Jos haluat vain lukea tietoja, tämä toimii, mutta on tehotonta isoilla olioilla.
Kaksi tapaa käydä vektori läpi:
1. Kopiointi (hidas, muutokset eivät vaikuta alkuperäiseen)
for(Student student: studentList){
student.setAge(25); // Muuttaa vain KOPION ikää, ei alkuperäistä!
}
2. Viittaus (nopea, muutokset vaikuttavat alkuperäiseen)
for(Student &student: studentList){
student.setAge(25); // Muuttaa alkuperäisen opiskelijan ikää!
}
3. Const-viittaus (nopea, ei voi muuttaa - SUOSITUS lukemiseen)
for(const Student &student: studentList){
student.printStudentData(); // Vain lukeminen, ei kopiointia
// student.setAge(25); // VIRHE: ei voi muuttaa const-viittausta
}
Yhteenveto:
for(Student student : list)- Kopioi olion, hidas, muutokset eivät vaikuta alkuperäiseenfor(Student &student : list)- Viittaus, nopea, voit muuttaa alkuperäistäfor(const Student &student : list)- Const-viittaus, nopea, vain lukeminen (PARAS tapa lukemiseen)
Suositus: Käytä aina const-viittausta (const Student&), kun haluat vain lukea tietoja. Se on nopea eikä kopioi olioita, mutta estää vahingossa tapahtuvat muutokset.
Esimerkissä 7 on käytetty smart_pointteria ja sen main.cpp on seuraava
#include "student.h"
#include <iostream>
#include <vector>
#include <memory>
using namespace std;
int main()
{
unique_ptr<vector<Student>> studentList = make_unique<vector<Student>>();
studentList->emplace_back("Teppo Testi", 1999, "TVT23SPL");
studentList->emplace_back("Liisa Joki", 1998, "TVT23SPL");
studentList->emplace_back("Aino Virta", 1997, "TVT23SPO");
studentList->emplace_back("Matti Virtanen", 2001, "TVT23SPO");
studentList->emplace_back("Mikko Vilkas", 2001, "TVT23SPL");
// Hae opiskelijalista studentList-osoittimesta
vector<Student>& students = *studentList;
for(int x=0; x<=4; x++){
// Käytä opiskelijalistan elementtiä `x` ja kutsu printStudentData() -funktiota
students[x].printStudentData();
}
return 0;
}
Esimerkki löytyy sivulta https://github.com/olio-kurssi/esim7
Edellä for silmukka voitaisiin korvata myös seuraavalla rakenteella, jossa ei tarvitse tietää montako alkiota vektorissa on.
for (Student &student : students) {
student.printStudentData();
}
Huom! Yleensä vektori kannattaa luoda pinoon, koska se on helpompi tapa. Tuota smart pointteria kannattaa käyttää vain, jos se on todella suuri.
emplace_back vs push_back: Esimerkeissä on käytetty emplace_back-metodia olioiden lisäämiseen vektoriin. Metodi emplace_back konstruoi olion suoraan vektoriin ottamalla vastaan konstruktorin parametrit, mikä on tehokkaampi tapa kuin push_back. Metodi push_back ottaa vastaan valmiin olion ja kopioi tai siirtää sen vektoriin, mikä voi vaatia ylimääräisiä kopio- tai siirto-operaatioita.
Esimerkki push_back-metodin käytöstä:
// Luodaan ensin Student-olio
Student student("Teppo Testi", 1999, "TVT23SPL");
// Lisätään olio vektoriin push_back-metodilla
studentList.push_back(student);
// Tai voidaan luoda olio suoraan push_back-kutsun yhteydessä
studentList.push_back(Student("Liisa Joki", 1998, "TVT23SPL"));
Vertailun vuoksi sama emplace_back-metodilla:
// emplace_back konstruoi olion suoraan vektoriin
studentList.emplace_back("Teppo Testi", 1999, "TVT23SPL");
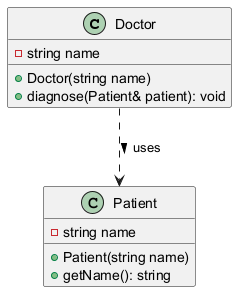
Assosiaatio tarkoittaa luokkien välistä yhteyttä, jossa toisen luokan oliot eivät omista toisen luokan olioita. Käytännössä tämä tarkoittaa että oliot ovat yhteydessä toisiinsa tilapäisesti, esimerkiksi metodin parametrina välitettynä viittauksena.
Esimerkki: Doctor-luokka ja Patient-luokka ovat assosiaatiossa. Käytännössä tämä tarkoittaa, että Doctor-olio voi käsitellä Patient-oliota metodissaan, mutta ei omista sitä. Molemmat oliot voivat olla olemassa itsenäisesti.
UML-diagrammi:
Assosiaation pääpiirteet:
- Oliot ovat yhteydessä toisiinsa, mutta eivät omista toisiaan
- Käytännössä yhteys toteutetaan tyypillisesti metodin parametrina
- Oliot voivat olla olemassa itsenäisesti toisistaan
- UML-diagrammissa merkitään katkoviivanuolella tai tavallisella viivalla
Käytännön ero koodissa:
Assosiaatiossa toisen luokan olio ei ole jäsenmuuttuja, vaan se välitetään metodille parametrina:
class Doctor {
private:
string name;
// EI Patient-jäsenmuuttujaa!
public:
void diagnose(const Patient& patient) { // Vain parametri
// Käyttää Patient-oliota tilapäisesti
}
};
Assosiaation erikoistapaukset:
Aggregaatiossa ja kompositiossa toisen luokan olio on jäsenmuuttuja:
- Aggregaatio (heikko kooste) = assosiaation erikoistapaus, jossa toinen luokka nähdään kokonaisuutena ja toinen sen osana. Osaluokan olio on jäsenmuuttuja, mutta osat voivat olla olemassa myös itsenäisesti
- Kompositio (vahva kooste) = vahvempi erikoistapaus aggregaatiosta. Osaluokan olio on jäsenmuuttuja ja osien elinkaari on sidottu kokonaisuuteen (kun kokonaisuus tuhoutuu, sen osatkin tuhoutuvat)
Koostaminen (composition) tarkoittaa "osa–kokonaisuus"-suhdetta luokkien välillä. Koostaminen voi olla joko heikkoa (aggregaatio) tai vahvaa (kompositio). Erona on, että aggregaatiossa osat voivat olla olemassa myös ilman kokonaisuutta, mutta kompositiossa eivät.
Aggregaatio on assosiaation erikoistapaus, jossa toinen luokka nähdään kokonaisuutena ja toinen sen osana. Osat voivat kuitenkin olla olemassa myös itsenäisesti ilman kokonaisuutta.
Esimerkki: Team-luokka koostuu Player-luokan olioista. Käytännössä tämä tarkoittaa, että Team-olio sisältää Player-olioita, mutta Player-oliot voivat olla olemassa ilman Team-oliota. Sama pelaaja-olio voi kuulua useampaan joukkue-olioon (jaettu omistajuus).
UML-diagrammi:
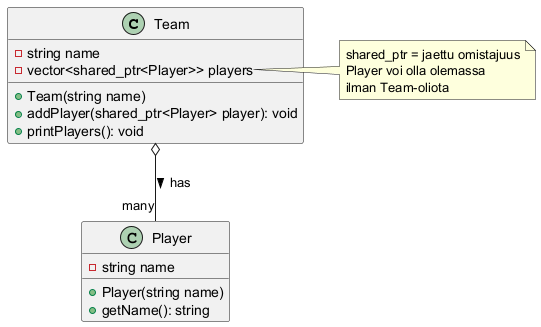
Aggregaation pääpiirteet:
- Osaluokan oliot ovat jäsenmuuttujia (toisin kuin assosiaatiossa)
- Sisältävä olio (Team) jakaa omistajuuden sisältämiensä olioiden kanssa (Player)
- Sama olio voi kuulua useampaan kokonaisuuteen
- Käytetään
shared_ptr:a jaetun omistajuuden ilmaisemiseen - Sisältämät oliot tuhoutuvat vasta kun kaikki viittaukset poistetaan
- UML-diagrammissa merkitään valkoisella vinoneliöllä
Käytännön toteutus koodissa:
class Team {
private:
vector<shared_ptr<Player>> players; // Jäsenmuuttuja!
public:
void addPlayer(shared_ptr<Player> player) {
players.push_back(player); // Tallennetaan luokkaan
}
};
Lisää esimerkkejä:
Kompositio on vahvin erikoistapaus aggregaatiosta. Suunnittelutasolla osien elinkaari on sidottu kokonaisuuteen. Käytännössä tämä tarkoittaa, että kun kokonaisuus-olio tuhoutuu, sen osa-oliotkin tuhoutuvat automaattisesti. Sisältävä olio omistaa sisältämänsä oliot.
Esimerkki: Car-luokka koostuu Engine-luokasta. Käytännössä tämä tarkoittaa, että Car-olio omistaa Engine-olion. Engine-olio ei voi olla olemassa ilman Car-oliota, ja kun Car-olio tuhoutuu, myös Engine-olio tuhoutuu automaattisesti.
UML-diagrammi:
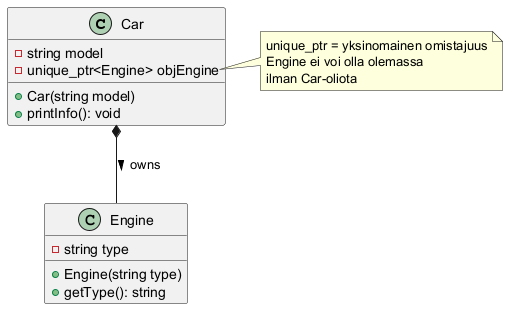
Komposition pääpiirteet:
- Osaluokan olio on jäsenmuuttuja (toisin kuin assosiaatiossa)
- Sisältävä olio (Car) omistaa sisältämänsä olion (Engine)
- Sisältämä olio luodaan sisältävän olion konstruktorissa
- Sisältämä olio tuhoutuu automaattisesti kun sisältävä olio tuhoutuu
- Käytetään
unique_ptr:ää yksinomaisen omistajuuden ilmaisemiseen - UML-diagrammissa merkitään mustalla vinoneliöllä
Käytännön toteutus koodissa:
class Car {
private:
unique_ptr<Engine> objEngine; // Jäsenmuuttuja!
public:
Car(const string& model) {
objEngine = make_unique<Engine>("V8"); // Luodaan konstruktorissa
}
// ~Car() tuhoaa automaattisesti myös objEngine:n
};
Miksi käyttää kompositiota?
Lisää esimerkkejä:
Kooste ja perintä ovat molemmat oliosuuntautuneita ohjelmistomalleja. Kooste tarkoittaa has a-tyyppistä suhdetta ja perintä is a-tyyppistä suhdetta. Tämän sivun esimerkeistä voidaan sanoa, että
- "Student is a Person", joten käytetään perintää
- "Classroom has a Student", joten käytetään koostetta
Abstrakti luokka, tarkoittaa luokkaa, josta ei voi luoda oliota, mutta luokkaa voidaan käyttää kantaluokkana muille luokille. Edellisessä esimerkissä voisimme tehdä Person luokasta abstraktin.
Edellisessä esimerkissä voit luoda Person luokasta olion. Luokka saadaan abstraktiksi, jos siihen lisätään yksi pure virtual method. Muutetaan Person luokassa sayStatus() metodin määrittely muotoon
virtual void sayStatus()=0;Funktion toteutus voidaan poistaa person.cpp tiedostosta. Nyt Person on abstrakti luokka ja jos, koetat luoda siitä olion, saat virheilmoituksen.
Esimerkki löytyy sivulta https://github.com/olio-kurssi/esim5
Virtuaalifunktioita sisältävän luokan tuhoajan pitää myös olla virtuaalinen.
Olio-ohjelmoinnissa käsite interface luokka tarkoittaa luokkaa, josta ei tehdä olioita. Siinä määritellään metodeja, muttei niiden toteutuksia. Siis määritetään metodien paluuarvojen tyypit ja parametrien tyypit. Kun jokin luokka perii tuon interface luokan on perivän luokan toteutettava interface luokan metodit, muuten seuraa virheilmoitus.
Javassa ja C#:ssa interface luokka toteutetaan lisäämällä sana interface luokan määrityksen eteen. C++:ssa ei tällaista sanaa ole vaan interface luokka voidaan toteuttaa tekemällä metodeista puhtaita virtuaalimetodeja. Interface luokan nimi alkaa usein kirjaimella I.
Tein esimerkin, jossa on interface luokka nimeltään IPerson ja Student ja Teacher perivät sen, sekä luokan Person. Esimerkki löytyy sivulta https://github.com/olio-kurssi/esim8
Staattinen luokka tarkoittaa luokkaa, jonka metodeita voidaan kutsua luomatta oliota kyseisestä luokasta. C++ kielessä ei voida luoda varsinaista staattista luokkaa, mutta toiminnallisesti käsitettä vastaa luokka, jonka kaikki metodit ovat staattisia.
Esimerkiksi C++:ssa on <cmath> kirjastossa funktio sqrt. Ei ole järkevää, että voidaksesi laskea neliöjuuren sinun tulisi luoda olio. Voit laskea esimerkiksi luvun 4 neliöjuuren koodilla std::sqrt(4.0).
Tein esimerkin, jossa on luokka nimeltään MyStaticClass ja siellä määritettynä metodi doubleMe. Luokan h-tiedostossa metodi on määritetty näin:
static double doubleMe(double);ja cpp-tiedostossa toteutettu näin:
double MyStaticClass::doubleMe(double value)
{
return 2*value;
}
Nyt tuota metodia kutsutaan main.cpp:ssä näin:
myResult=MyStaticClass::doubleMe(myValue);Metodia siis kutsutaan syntaksilla luokan nimi :: metodin nimi
Voit kuitenkin luoda olioita luokasta MyStaticClass. Jos haluat estää olioiden luomisen, voit muokata luokan oletusmuodostimen h-tiedosssa seuraavaan muotoon:
MyStaticClass()=delete;
Esimerkki löytyy sivulta https://github.com/olio-kurssi/esim9
UML eli Unified Modeling Language on standardoitu tapa kuvata ohjelmisto- ja järjestelmäsuunnittelua visuaalisesti. Se tarjoaa erilaisia kaavioita ja työkaluja ohjelmistojen rakenteen, toiminnallisuuden ja käyttötapauksien mallintamiseen. UML auttaa suunnittelijoita kommunikoimaan, ymmärtämään ja dokumentoimaan ohjelmistojen arkkitehtuuria ja toiminnallisuutta.
Luokkakaavio on UML-standardin mukainen mallinnustyyppi, joka kuvaa järjestelmän staattisen rakenteen luokkien ja niiden välisten suhteiden avulla.
Luokka piirretään suorakaiteena, joka on jaettu kolmeen osaan; luokan nimi, luokan tiedot (jäsenmuuttujat) ja luokan toiminnallisuus (jäsenfunktiot).

Diagrammeissa käytetyt suojaustasoa kuvaavat symbolit ovat:
- - : private
- + : public
- # : protected
Esimerkiksi jäsenmuuttuja osiossa voisi olla rivi:
-age:int
joka tarkoittaa, että luokka sisältää int tyyppisen muuttujan nimeltään age, jonka suojaustaso on private
Ja jäsenfunktio osiossa voisi olla rivi:
+getInfo(int):float
joka tarkoittaa, että public metodi getInfo ottaa vastaan argumenttina int tyyppisen arvon ja palauttaa float tyyppisen arvon
Kontruktoria ei välttämättä merkitä diagrammiin.
Periytyminen ilmaistaan diagrammeissa nuolella, jossa nuoli osoittaa perittävään luokkaan seuraavasti:
Kooste ilmaistaan diagrammeissa viivalla, jossa vinoneliö osoittaa koostavaan luokkaan seuraavasti:
Huom! Musta vinoneneliö ilmaisee, että kyseessä on vahva kooste.
auto on C++11:ssä esitelty avainsana, joka mahdollistaa tyyppi-inferenssin eli kääntäjä päättelee muuttujan tyypin automaattisesti annetun arvon perusteella.
Perusesimerkki:
// Perinteinen tapa - eksplisiittinen tyyppi int age = 25; string name = "Teppo"; double price = 19.99; // Auto - kääntäjä päättelee tyypin auto age = 25; // Tyyppi: int auto name = "Teppo"; // Tyyppi: const char* (HUOM!) auto price = 19.99; // Tyyppi: double
Hyödylliset käyttötapaukset:
1. Smart pointerit - koodi selkeämpää
// Ilman autoa - pitkä ja toistuva unique_ptr<Person> p1 = make_unique<Person>(); shared_ptr<Student> s1 = make_shared<Student>(); // Autolla - lyhyempi ja selkeämpi auto p1 = make_unique<Person>(); auto s1 = make_shared<Student>();
2. For-silmukat - erityisen hyödyllinen
vector<Student> studentList;
// Ilman autoa
for(const Student &student : studentList) {
student.printStudentData();
}
// Autolla - yhtä selkeä, vähemmän kirjoitusta
for(const auto &student : studentList) {
student.printStudentData();
}
3. Monimutkaiset tyypit
// Ilman autoa - vaikealukuista // begin() palauttaa iteraattorin (osoittimen kaltainen objekti) vektorin alkuun vector<unique_ptr<Student>>::iterator it = studentList.begin(); // Autolla - paljon selkeämpi, kääntäjä päättelee tyypin auto it = studentList.begin();
Milloin VÄLTTÄÄ auto:a:
Varoitus: Auto:n liiallinen käyttö
- Oppimisen alkuvaiheessa: Eksplisiittiset tyypit auttavat ymmärtämään, mitä koodissa todella tapahtuu. Käytä
int age = 25;eikäauto age = 25;kun opettelet. - Kun tyyppi ei ole selvä:
auto result = calculateSomething();- mikä on result:n tyyppi? Eksplisiittinen tyyppi dokumentoi koodia paremmin. - String-literaaleissa:
auto name = "Teppo";on tyyppiäconst char*, eistring! Käytästring name = "Teppo";taiauto name = string("Teppo");
Hyvät käytännöt:
- Käytä
auto:a kun tyyppi on ilmeinen oikean puolen perusteella (esim.make_unique,make_shared) - Käytä
auto:a for-silmukoissa, erityisesti const-viittausten kanssa:for(const auto &item : list) - Käytä
auto:a kun tyyppi on pitkä ja monimutkainen (esim. iteraattorit) - Käytä eksplisiittisiä tyyppejä kun haluat dokumentoida koodia selkeästi
- Oppimisen alkuvaiheessa käytä eksplisiittisiä tyyppejä ymmärryksen parantamiseksi
Auto ja viittaukset:
Person p; auto p1 = p; // Kopioi p:n -> p1 on tyyppiä Person auto &p2 = p; // Viittaus p:hen -> p2 on tyyppiä Person& const auto &p3 = p; // Const-viittaus -> p3 on tyyppiä const Person& p1.setAge(25); // Muuttaa vain p1:n ikää p2.setAge(30); // Muuttaa p:n ikää (viittaus!) // p3.setAge(35); // VIRHE: const-viittaus
Yhteenveto:
autoon hyödyllinen työkalu, joka tekee koodista lyhyempää ja helpommin ylläpidettävää- Erityisen hyödyllinen smart pointereiden, for-silmukoiden ja monimutkaisten tyyppien kanssa
- Oppimisen alkuvaiheessa käytä eksplisiittisiä tyyppejä ymmärtääksesi paremmin mitä tapahtuu
- Kun ymmärrät tyypit ja niiden toiminnan, voit alkaa käyttää
auto:a järkevästi - Älä käytä
auto:a vain siksi että se on lyhyempi - käytä sitä kun se tekee koodista selkeämpää
Oppaaseen liittyvien esimerkkien lähdekoodit löytyy sivulta https://github.com/orgs/olio-kurssi.
| repository | aihe |
|---|---|
| esim0 | Tietue |
| esim1 | Luokka ja olio (pino ja keko) |
| esim2 | Muodostin ja tuhoaja |
| esim3 | Periytyminen |
| esim4 | Virtuaalimetodi |
| esim5 | Abstraktiluokka |
| esim6 | Vahva kooste |
| esim6b | Heikko kooste |
| esim7 | Oliotaulukko |
| esim8 | Interface luokka |
| esim9 | Staattinen luokka |
| unit_test | Yksikkötestaus |