Nowadays MongoDB documentation suggest to use Aggregation Pipeline instead of MapReduce, because the aggregation pipeline provides better performance and usability than a map-reduce operation.
MapReduce is a fairly popular approach used to distribute computing across many threads or nodes. MongoDB supports MapReduce. MapReduce is designed to handle extremely large data sets.
Overview
MapReduce is a framework for processing problems across large data sets using many nodes for massive parallelization. Inspired by functional programming, it was introduced by Google in 2004. It primarily consists of a map function to be run many times in parallel and a reduce function that takes the output (emits) from all the maps and "reduces" them down to a single value for each key or in the case of emitting an array, a set of values for each key. Each implementation of MapReduce is slightly different, and MongoDB is no exception. In MongoDB, only two methods are required: the Map and Reduce methods. Additional helper methods are also available to group, sort, and finalize the data. Below picture shows the principe of MapReduce in Mongo.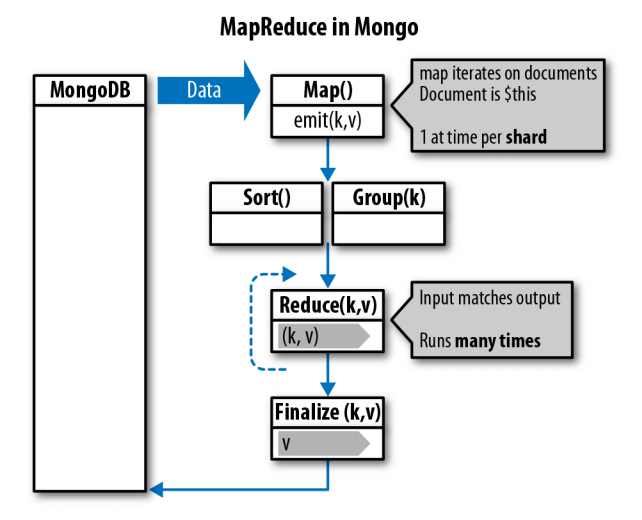
Example
You can find an example about MapReduce in Mongos documentation: http://docs.mongodb.org/manual/core/map-reduce/.
In order to test this example, lets create a database and a collection and add the data:
use mrExample
db.createCollection("orders")
db.orders.insert({cust_id: "A123",amount:500,status:"A"})
db.orders.insert({cust_id: "A123",amount:250,status:"A"})
db.orders.insert({cust_id: "B212",amount:200,status:"A"})
db.orders.insert({cust_id: "A123",amount:300,status:"D"})
And then the execute below code in order to create a new collection named order_totals
db.orders.mapReduce(
function() { emit(this.cust_id, this.amount); },
function(key, values) {return Array.sum(values) },
{
query: {status: "A" },
out: "order_totals"
}
)
So now we have a new collection named order_totals, which has below documents:
{ "_id" : "A123", "value" : 750 }
{ "_id" : "B212", "value" : 200 }
You can make the above example using aggregation pipeline framework like this :
db.orders.aggregate([
{ $match: { status: "A" } },
{ $group: { _id: "$cust_id", total: { $sum: "$amount" } } }
])
With above code you will see the results in the screen. If you want to put the results in a collection (named aggr_orders), you can use below code
db.orders.aggregate([
{ $match: { status: "A" } },
{ $group: { _id: "$cust_id", total: { $sum: "$amount" } } },
{ $out : 'aggr_orders' }
])
Here is a video about Aggregation Pipeline https://www.coursera.org/lecture/big-data-integration-processing/aggregation-operations-in-big-data-pipelines-VDBgw